|
|
| Home
Getting Started Download Documentation API Docs Reference FAQ EJB 3.0 Support Contact Viewpoint |
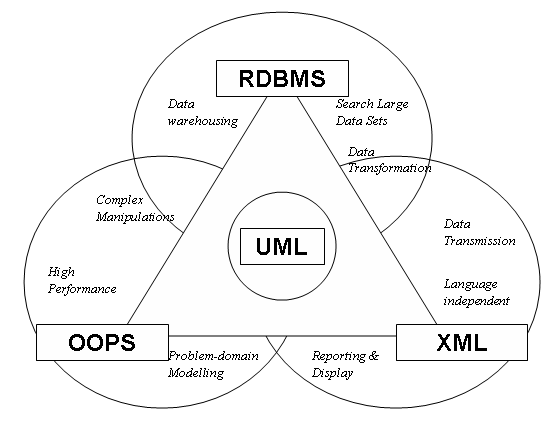
What is Hydrate?Hydrate is a Java tool that provides for fast efficient and
error-free transformation of data between three different
representations: relational databases, objects in an object-oriented
programming language and extended markup language (XML). Each of
these representations has its strengths and weaknesses as shown in
the diagram below; but which should you use as a basis for your
application design?
Hydrate relaxes some of the pressure on this decision by providing tools for moving data from one representation to another, guided by a master UML class representation of that data. When Should I Use Hydrate?Here are few example situations in which Hydrate will significantly reduce the amount of development effort required to create a solution:
When Should I Not Use Hydrate?Object/Relational and Object/XML mappings are both fields with a lot of interest and support and Hydrate does not pretend to be the best solution for all applications. Here we highlight where you might be better off looking at other solutions:
What are Hydrate's Key Features?
What Are Hydrate's Innovations?These are the techincal innovations in Hydrate that are found
in very few other products in the Object/Relational mapping and SQL
Mapping space.
Multiple object types and relationships loaded from a single query.You can simultaneously map any number of object types from
your query and link them up according to your declared relationships
(one-to-many, many-to-many, etc.), all in a single operation.
Hydrate automatically takes care of resolving repeated object data from
the query to a single object. This powerful feature Order independent mapping of queries and XML data.You have a huge amount of flexibility in mapping from queries/XML to your object model. You can run as many or as few queries as you need to pull into memory the data that you need for a particular calculation or report. You can go to multiple data sources and/or read data from mutliple XML schemas. You are free to execute these queries or XML parses in any order. For example loading 'child' objects first then 'parent' objects works equally as well as loading 'parent' then 'child'. The decision about which to use can be made based on your particular situation, for best possible clarity and performance.All or part of an object can be 'not set'.All commercial relational databases have a special value for
eligible columns of 'null'. This indicates that there is no value
appropriate for a particular column, and, notwithstanding the debate
about how exactly null should be used, or how many different types of
'null' there are, it is generally found to be useful in database
design. Object models tend to be quite poor in representing
'nulls' in code. They are either ignored or mapped as object
types which is very costly for an attribute that would otherwise be a
native type. Hydrate adopts conventions so that all optional
fields (other than boolean) can have a value of not set, equivalent to
'null' in the database. All or part of an object can be 'not loaded'.In Hydrate, each column (including booleans) can have another
special value of 'not loaded'. This means that the value has not
yet been read from any data source (query or XML). This simple
feature is incredibly powerful since it allows us to partially populate
any part of an object, populate different parts of the same object from
different data sources, or lazily load all or parts of an object.
Hydrate continues to use native types reference and store attributes. Multiple candidate keys supported and automatically reindexed.Each object can have multiple candidate keys, both simple and composite. This means that you can load different information about the same object from different data sources that have a different way of keying your object. Indexes are automatically maintained to permit fast look-up by key, and these are automatically rehashed when any part of the composite key changes.Composite keys may recursively include foreign key fields.For object models that do not use surrogate keys, part or all
of the primary key of an object is often a reference to another
object. If that object's primary key also includes a foreign key
reference, you end up with some quite complex naming and mapping
problems. However, this model is often very useful particularly
if you are using your default relational schema as a place to cache
results, since it avoids unneccessary joins when retrieving data.
Hydrate supports any level of recursion for foreign key fields in
primary keys. Automatic reverse reference fixup.Bidirectional references create a relationship between the
corresponding bean properties in the two objects that refer to one
another. Take the simple case of a bidirectional one-to-one
relationship: person to spouse. If we establish this link between
Alice and Bob by invoking alice.setSpouse(bob), then in order to keep
the model consistent, we must also call bob.setSpouse(alice).
However, before doing this we need to disentangle both Bob and Alice
from any existing relationships by invoking
bob.getSpouse().setSpouse(null) and
alice.getSpouse().setSpouse(null). The exact sequence of
operations that needs to be performed to ensure that these
relationships remain consistent depends on the relationship type
(one-to-one, one-to-many, or many-to-many) and whether the to-one
relationships are optional or mandatory. This is error prone if
left up to developers and can lead to problems that are very hard to
track down. Hydrate writes all of this code for you
automatically. XML Schemas tightly integrated with the object model.An XML schema is a hierarchical representation of a data model. Given any non-trivial UML object model there are any number of hierarchies that you could draw through it moving along the navigable relationships of the object model. Hydrate's knowledge of the structure and relationships between objects makes it very simple to declare one or more such hierarchies and Hydrate will then generate a full typed XSD schema and the code to write and read XML compatible with that schema from a set of objects in memory. This turns out to be very useful in passing object models over a serialized connection, saving cached versions of object model and reporting or displaying data through XSLT.Where Can I Download A Copy?The latest release of Hydrate can be found here.
|