 |
||||||||||||||||||||||
| Home Getting Started Download Documentation API Docs Reference FAQ EJB 3.0 Support Contact Viewpoint |
Getting Started With Hydrate
|
|||||||||||||||||||||
java -version |
Check that you are picking up the correct version of both
tools.
(b) To build the application (if you want to build from source) you
will need a copy of apache ant (we're
using version 1.6.5), which can be downloaded from apache's website at http://ant.apache.org/bindownload.cgi
(c) To run the tests, you'll need to download a copy of
MySQL. We are testing against MySQL 5.0 so as we can include
tests for stored procedures. Download this from http://dev.mysql.com/downloads/.
You only need this if you want
to view the testing database and run the full test suite.
2. Get the latest version of Hydrate
Go to http://sourceforge.net/project/showfiles.php?group_id=146051
to download Hydrate software. All packaged releases contain the
same files and there are scripts for linux and windows based
systems. Pick the format that most suits the tools you have on
your system.
3. Run the user interface. To start the Hydrate UI, run the following:
For linux where <hydrate home> is the root directory of
the files you unzipped:
cd <hydrate home> |
For windows:
cd <hydrate home> |
You should see a display that appears something like the
following:
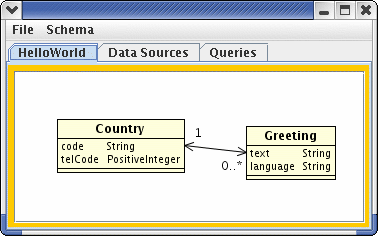
This is a picture of the data model as described by your UML
definition file that we want to lay over the top of the relational
database that has been given to us. You choose this object model
based on your operational requirements - it does not have to be
modelled exactly according to your relational data. The features
of Hydrate permit you to map any
underlying relational model that has the right data in it to this
object model.
The following XML definition file has been written to describe the above UML:
<?xml version="1.0" encoding="UTF-8"?> |
The Hydrate UI is a tool that allows you to visualize your data model, examine the relationships between the objects, customize the way you want the objects layed out and, most importantly, write and test queries that you can use to access the data. You have just started the UI with the 'HelloWorld' model. This is the model that is used in the basic 'HelloWorld' application, and we'll be using the same model in this short tutorial.
Look at the model as shown to you. You'll see that it takes the form of a UML class diagram, with two classes having a one-to-many relationship between them. Each object has a name and a list of typed attributes: you can see more detail about the object by double clicking it so see the object details page. Each relationship links two objects and again can be viewed in more detail by double clicking the link. The only editing currently permitted by the UI enables you to position the classes relative to one another and save the results. Object definitions are edited through the XML definition file, although you will be able to do this in the UI in future releases. You can see the definition file that defines this model by opening <hydrate home>/HydrateSample/Sample/HelloWorld.xml in a text editor.
Note that this model has been kept simple for clarity.
Hydrate permits much more complex object models including different
types of relationship (one-to-one and many-to-many, optionally
navigable in either direction), as well as single inhertitance
hierarchies.
The HelloWorld Continued application demonstrates how, with
Hydrate you can take an arbitrary data model given to you in a
relational database, pull that model into an object model chosen by you
in a number of different ways (each with their own performance
characteristics), write the resultant model to an XML document whose
structure is chosen by you. Here's a schematic of what it does:

4. Check the data sources and queries
In addition to providing a visualization of the model, the tool also acts as a query builder that lets you write SQL queries against any data source and map the resulting record set to your object model. This tool can also act as a point to gather together all of the queries that you are using in your application and perform some basic testing to ensure that all continue to function correctly.
Before writing queries you have to set up the data sources that your application will use. Click on the 'Data Sources' tab to see the list that has been set up for the sample application. There is a single data source declared that connects to an instance of 'tiny SQL' - another open source project with source available here: http://sourceforge.net/projects/tinysql/. This is a convenient database to use for testing since it can be distributed in a single jar file, and the database tables can each be distributed in a single file. Tiny SQL is also a good demonstration of the fact that hydrate works as well for a minimal JDBC driver as for more fully featured ones. The database that this data source connects to is a small database containing two tables: 'GREETINGS' and 'COUNTRIES', that will be used by the HelloWorld sample application.

Now select the 'Queries' tab on the UI. Here you see the set of
queries that will be used in the sample application. Each row
represents a named query that has been configured to load objects in
your model from the database. Select a row and click 'Edit' or
double click the row to open the query builder dialog box. The
query builder is a modeless dialog so you can open up an editor for
each query in the list and for one new query. You can then go
back to the main window to edit the datasources or view the object
model (which is especially useful). Each query
includes the SQL to be run, an optional WHERE clause and information
about how the results will be mapped into an object or objects in the
model. Double click on the 'AllCountriesAndGreetings' query to
see how a
simple query is created.

The boxes with white backgrounds and the combo boxes are where
you can enter data. Here's an explanation of what appears in this
edit interface:
- Name: the name of the query - use this edit box to choose a unique name by which this query will be identified. This name is also used, with an extension of ".xml" to make the file name for the query definition file.
- Description - a text description for the query. Use this box to enter information about what the query does. You should make good use of this feature as this will assist greatly in your ability to reuse existing queries.
- Datasource Name - this restricted combo-box lists the set of data sources that you have set up on the previous tab. You must select one of these to indicate where the query should go to retrieve data.
- No Prepare - select this checkbox if you don't want your queries to use prepared statements (which is the default). You only need to check this box if you are using a simple JDBC driver that either does not fully support prepared statements (as is the case with TinySQL), or for which the implementation results in performance degredation.
- Enter SQL Expression - this box is used to enter details of your query. You can type any query into this box and with the exception of the WHEREn clauses described below, this is exactly what will be sent to your JDBC driver.
- Where Expression - type expressions that may form part of the WHERE clause into this section. This is described in more detail below.
- Parameters - any parameters that you have outlined in the Where Expression will appear in this list. It updates automatically whenever an epression is added or removed. The first two columns list the name of the parameter and its type respectively. You can enter a value in the last column for each of the parameters or leave them blank for 'not set'.
- Rowcount limit - use this box to type a number of rows to which the displayed result set will be limited.
- View Results - click this button after making a change to the query in the 'Query' box, or to one or more of the Where Expressions or Parameters. The new query will be constructed, executed with the new parameters, and the results displayed in the results window
- Executed SQL and Other Messages - This contains the constructed query (as a prepared statement) that was run against the database including the constructed where clause. If an error occurs it contains the error. You cannot edit the information in this box.
- Results From the Query - The results grid shows the output of the query. When you first open the dialog box, or when you click the 'View Results' button, this results grid is filled with the first 'n' rows returned from the query. This happens in a background thread, so for complex queries, it amy not appear immediately.
- Mappings from Columns To Object Attributes - This is the
most important element of the query map dialog. Each of the rows
contains an object map, that is
maps some of the resulting columns in the query to a single object in
your model and declares how that should link to other objects.
There is no limit to the number of object maps that can be applied to
the results of a single query. The process of setting up the
object maps is described below.
5. Look more closely at the query builder
The job of the query builder is simply to take the 'flat' set of query results and map those results into the objects in your model.
The first section of the dialog allows you to enter the basic
features of the query. The name, a description, the name of the
datasource that the query will be going to (which must be a datasource
configured in the datasource tab). At the end of this section,
the 'no prepare' tab is used to veto the default use of prepared
statements (for drivers that do not support them).
The query's select statement follows; for the
AllCountriesAndGreetings
query we are selecting everything from the Greetings table. The
query takes the form:
SELECT * FROM GREETINGS, COUNTRIES WHERE1 |
Note that the token 'WHERE1' is a placeholder for the WHERE
clause of the SQL statement. The actual WHERE clause is
constructed dynamically from the list of expressions that appears
below. This is a 'reverse polish' boolean expression. See here for a broad
description of how reverse polish notation works.
Each line in this expression list is either a boolean
expression or one of the boolean operator words 'AND', 'OR' or
'NOT'. The boolean expressions are permitted to contain named
parameters of the form
[name:Type] |
meaning a parameter called 'name' of type 'Type'.
At runtime, you can decide which of these parameters you
supply and which you leave unspecified. By providing different
combinations of the available parameters you have unprecendented
control over the query that is run against the database. Consider
- If you leave all parameters unset, the AllCountriesAndGreetings query will select all countries and greetings that are present in the database.
- If you set the 'country' parameter, the query will select only those greetings with the country details, where the country short code is as specified by the parameter.
- If you set the 'telCode' parameter, the query will select only those greetings with the country details, where the country telephone code is as specified by the parameter.
- If you set both the 'country' and the 'telCode' parameter, the query will select greetings where the country is either the code given by the country parameter or the number given by the telCode parameter.
Try entering a few different values for the 'country' parameter to see the effect on the query and its results. Try deleting the parameter value (not the expression). Note that the where clause disappears entirely if no parameters are set.
The query builder shows the first few results from the query in the query grid at the bottom of the screen. In the grid below, the developer chooses how to map these results into the objects that have been described in the model. The process of mapping is very simple:
- Choose an object to map
- Choose a key to be used to detect/resolve duplicates
- Choose the fields to be mapped (which can be as many as the developer wishes, but must at least include the fields that are part of the chosen key)
- Repeat for all other objects to be mapped
- Provide linkage information between objects in the "Link To" column.
With reference to the query grid shown below, you can see that
in the case of the AllGreetings query, we are
mapping two objects: Greeting and Country. The greeting object
has no key defined, which means that every row of the query will always
create a new Greeting object. The columns mapped for Greeting
are: 'LANGUAGE' -> 'language' and 'GREETING' -> 'text'. We
have chosen not to map the generated '_id' column - because there is
nothing in this database for it to map to. Hydrate has no
problems about creating your object with any attributes missing, even
attributes of the primary key. The country object has a key
defined: CountryKey, which happens to be the primary key of the object
- but does not have to be. Since we have a key, we must at least
map the field or fields that make up that key, in this case 'COUNTRY'
-> 'code'. By including a key in the country mapping Hydrate
will automatically eliminate duplicate country objects so that only one
country object representing 'GB' will be created even though there are
two records that have this country. Only the key attribute of
country is populated because that is all that is available from this
query.

Finally, the query builder requires you to declare the linkage between
the objects that you are mapping. The builder knows a lot about
which linkages are possible, but will generally need a bit of help in
determining which object should link to which. You specify the
linkage in one of the 'LinkTo' columns to the right of the query
results and you are helped in your selection by a drop-down list that
shows all possible values. In this case there is only one
possibility, but you still have to select it.
There are three more queries that have been defined and are used as
part of the HelloWorld Continued sample application.
6. More tools on the UI
The UI provides access to two other useful functions: first
you can start the code generation process. Select Schema/Generate
classes and enter the root direction for the generated classes.
Select an SQL dialect of 'TinySQL' and the check box for compilation
and click Ok. The UI now kicks off the code generation process
and runs the java compiler to compile the generated sources. You
get a report showing the files that were generated.
Next, the UI provides a tool for testing all of your queries.
Select Test Queries from the File menu and the Hydrate UI will go
through each of the queries that you have declared ensuring that they
run without error, and that the columns that you have declared to be
mapped are available from the result set. By placing all your
application's queries under Hydrate's control, you have a quick way of
smoke-testing your application after any database change. The
collection of queries could easily form the basis of a more extensive
regression testing suite as well.
Both of these tools: code generation and query testing are also
available from the command-line and as ant tasks.
7. The Hello World Continued application - retrieving data
You will now go on to use the model you have generated to hydrate data from a database into an object model in a number of different ways.
The HelloWorld Continued application is an extension of the Hydrate HelloWorld application. This latter application demonstrates how Hydrate can be used to select an appropriate 'hello world'-style greeting, based on locale, from a selection that have been saved in a relational database. The 'continued' application goes on to demonstrate how Hydrate permits you to choose many different ways of reading the same data, and how it provides tools for writing that data back to a default database schema and/or to XML.
Open the Hello World Continued application in your favourite editor/viewer and take a look at the 'main' method. This method establishes the directory of the database to be used for the test, sets up the environment (setUp), runs some tests that compare the performance of four different ways of loading the same information into memory (runLoadTests), demonstrates how a script to build a default database is generated (createDefDatabase), and shows how information can be written to the default database and read from and written to XML.
Let's look at the load tests first. The HelloWorld
application started by reading all the greetings and countries from the
database, then selected the country that was the same as the default
locale and printed out the greetings associated with it. Now the
printing of greetings and their retrieval from the database are two
operations that have different conflicting constraints. While for
retrieval of data from the database we are generally most interested in
grabbing the right data as quickly as possible and handling the raw
data types as they are returned, in the object space we are trying to
work with clear and concise domain model that is independent from how
the data is retrieved.
One important job of a good object-oriented mapping layer is to decouple these two conficting sets of requirements so that one has the flexibility to change without affecting the other. Suppose we need to change the retrieval from the database so that a different database is used that perhaps doesn't support joins or only has partial data. We don't want to have to change the 'business logic' when we make this change, just the way that the data we have is mapped into the objects that we are working with. Obviously the business logic in this example is not sufficiently complex for this to really be a problem, but consider if instead of printing out friendly greetings, our application was compiling optimized order schedules for multiple wholesalers, or calculating the price of thousands of different financial instruments in real time.
The load tests basically do the same thing four times: they load all (well almost all) the greeting and country data into memory so that the correct greeting can be chosen. But what is the best way to do this? Should we load all the greetings, then, for each unique country load in information about the country? Should we load in all the countries and then all the greetings (making sure that they link up properly)? But this will load countries that have no associated greetings, so, should we only load those countries that have greetings, then all the greetings? Finally, we could permit the database to join information and load all greetings and countries together.
Here is an example of the code for the three scenarios
1. All greetings in the database with links to countries, then
each country one at a time.
// load in all greetings and their references to countries |
2. All countries, then all greetings and their links to countries
// load in all countries (whether used or not) |
3. All countries that have at least one greeting, then all greetings
and their links to countries
qry = new QueryMap(ctx, "UsedCountries.xml"); |
4. All greetings and all countries together.
// load in all greetings and their references to countries with full country details |
These four scenarios essentially do the same thing, and illustrate how
different population strategies can result in slightly different sets
of objects being read into memory in different orders. Hydrate
permits you to load countries first, then greetings or greetings first
and then countries. You can read in all or part of any object, so
there is no problem with some objects having the key only populated,
others missing the telephone code, etc, (until you actually try to use
the data of course).
Each of the four scenarios can be expected to exhibit different
performance charactersitics. In order to get a reasonable picture
of performance, all query strategies are executed 501 times in the
HelloWorld Continued application. The
first run is ignored for the performance calculation, and the remaining
500 are averaged out to give a figure in milliseconds. At the end
of the test run the loaded objects are printed out as an XML document
(the code to write this was generated in the code generation step).
So which is quickest? Perhaps unsuprisingly the single query that
returns both Countries and Greetings runs fastest, though not much
slower than the one that loads all Countries and all Greetings.
The slowest by far is the first, that retrieved all Greetings, then the
countries one at a time. This is interesting, because the
majority of O/R solutions can only do this kind of mapping.
Of course, you are probably asking why did we load all countries and
greetings into memory when all we needed were the country and greetings
for the current locale. A good question indeed and it is a very
simple thing to do, to add a filter to the SQL so that only those rows
are returned. Try using the following query to populate data:
qry = new QueryMap(ctx, "AllCountriesAndGreetings.xml"); |
Having said that, you may be surprised by the fact that it is not massively quicker than the unfiltered version. Sometimes, it may be better to pull in more information than you strictly need because it prevents business logic seepage - in which little bits of business logic (in this case "I am only interested in greetings from the country in the default locale") leach out into your database access code.
The most important point is that we have now tried out five different ways of populating the same object model, making use of whatever tricks our SQL engine could muster but the business logic, that makes use of the data returned from the database has not changed at all. In effect we have decoupled data sourcing and business logic.
8. The Hello World Continued Application - XML
As part of the data retrieval part of the application, we also
demonstrate the ability to write XML. The next part of the sample
application will go on to read this XML back into objects and go on to
save this model into the default database. This section covers
the writing and reading of XML. This is a feature offered
by many frameworks, but Hydrate's implementation is well integrated
with the object model definition and is highly performant using SAX
exclusively. The definition file for the model contains the
following XML snippit that defines an XML Schema.
<XMLSchema name="Greetings"> |
This effectively declares a route through the object model that an XML hierarchy should take. In the case of the simple database, with just two objects, there are only two possible routes: we could either start at Country and then show a list of Greetings, or start a Greeting and show the detail of the country as a sub-element. Both representations are equally valid, and equally useful depending on the situation. Here we have chosen to start at Country. In a more complex model, any number of possible hierarchies through the model might be possible.
This definition generates an XSD schema that defines the XML model and a 'ParserWriter' class that knows how to write and read objects that conform to this schema. Here is the generated XSD schema definition file for this model:
<?xml version="1.0" encoding="UTF-8"?> |
And here is an example of an XML document that was produced by
the generated ParserWriter class as part of the data retrieval
example. If you run the application you will see that it prints
out documents like this to prove that the data retrieval is reading the
correct objects from the database. This XML document has been
constructed in such a way that the objects that created it can be
easily reconstituted back into memory by rereading the document using
the same ParserWriter generated class.
<Greetings xmlns="uri:org.hydrateframework.sample.model" |
At the end of the runLoadTests method in the
HelloWorldContinued application it actually writes out a file
which should match the aboce into
'tinySQLDefDatabase/Data.xml' that contains the last copy of the data
read from the database. This forms a copy of the objects in
memory that can be used to reconsistute exactly the same object model
back into memory without going to the original relational data
source. As the first part of the save-to-database demonstration
decribed below, it uses this XML data file to
create the object model which will be saved down to the default
database.
The template code needed to create a SAX handler which will
write to a file is wrapped in the makeSAXHandler method. This is
standard XML SAX code - see http://xml.apache.org/xalan-j/apidocs/org/apache/xml/serializer/Serializer.html
for details. Once created, the generated GreetinsXML class writes
out the XML document.
ContentHandler fileSAXOut = makeSAXHandler(fileOut); |
When it comes to reading the file back into memory, the code
creates a
SAXParser - again part of the JAXP infrastructure (see http://xml.apache.org/xerces2-j/faq-sax.html).
This parses
the document we wrote earlier, and creates objects in a new
ObjectContext:
final SAXParserFactory spf = SAXParserFactory.newInstance(); |
9. The Hello World Continued Application - The default database.
As part of the code generation step, you will have been given
a script,
in data definition language (DDL) that, when run on your chosen
database, will create the tables you need to store the model described
in you definition file. Also generated are is a query for each
object type in your model to read and write that object from the
default data model. Actually, when reading, you'll probably want
to write your own queries and then map them to the model in order to
make the most of your database's performance, but for writing, it is
generally most convenient to use the queries that were written for
you. Let's have a look at the generated database read/write code.
DROP TABLE GREETING; |
In the createDefDatabase method of the HelloWorldContinued application, the code opens this generated DDL file (from the classpath), and reads it in a line at a time. Each time the ';' terminator is detected, the command is printed to stdout and sent to the database driver. You can see that the script drops, then recreates two tables: COUNTRY and GREETING. This DDL is very simple because the TinySQL database is a very simple database. You do not have any indexes, primary or foreign keys, autonumbered columns, or even VARCHAR fields in this implementation because they are not supported by TinySQL. If you choose another SQL dialect (for example DB2) to create your DDL, these clauses will be included.
The databases are initially empty and the HelloWorld Continued application goes on to populate them with data. In the saveToDefDatabase method, the code reads in the object model from XML (more about this later) and then writes it to the default database we have just created. In effect, all the method needs to do to save the model down to the default database is to call:
ctx.saveAll() |
This iterates through all objects that have changed and
updates or
inserts them (as appropriate) into a database using the default queries
- in this case those that were automatically generated for us.
The method finishes up by printing out the contents of the tables we
have just written, producing an output something like:
CODE NAME TELCODE |
10. Summary
To run the sample application type the following for linux:
cd <hydrate home> |
For windows:
cd <hydrate home> |
Here ends our brief tour of the features of Hydrate.
You should have seen how Hydrate permits you to This was
necessarily a simple example with a small database and a basic JDBC
driver, but Hydrate comes into its own with much larger, more complex
object models, bigger databases and industrial strength, JDBC drivers.